 VNN Everything about virtual voices, just one click away!
VNN Everything about virtual voices, just one click away!

Récemment, nous avons beaucoup parlé de Synthesizer V, un des nouveaux logiciels synthétiseurs les plus récents et les plus attendus, développé par Dreamtonics. Nous avons aussi beaucoup parlé des nouvelles banques vocales qui ont été ajoutées au sein de Synth V : GENBU, Yamine Renri et bien sûr, AiKO, sa première banque vocale commerciale chinoise. Maintenant, nous avons la chance d’interviewer Kanru Hua et de parler avec lui de leur logiciel, et tout ça pour VNN ! C’était vraiment un honneur pour nous et nous sommes très heureux d’avoir pu l’interviewer. Vous pouvez lire l’interview ci-dessous, en espérant que ça vous plaira !
Dorelly : Bonjour, et ravie de te rencontrer ! Merci beaucoup de me laisser l’occasion de t’interviewer ! Je me sens honorée !
Kanru : Pas besoin d’être aussi formelle *rire*. Tu es aussi étudiante en informatique, pas vrai ?
Dorelly : C’est exact, et j’ai moi-même toujours été intéressée par les Synthétiseurs. En fait, j’ai été très heureuse quand j’ai vu ton Moresampler pour UTAU la première fois, et la première chose que je me suis dit, c’était « Oh mon dieu je ne suis pas toute seule ! »
Kanru : La curiosité est une bonne chose. J’ai voulu créer quelque chose qui était « purement subjuguant » comme personne n’en n’a jamais vu avant, haha.
Dorelly : Oh, j’ai senti cette aura avec Synth V ! Quand est-ce que tu as commencé à travailler dessus ?
Kanru : L’idée (technologiquement parlant) m’est venue vers début 2015. Mais à l’époque, les technologies n’étaient pas assez développées pour être utilisées pour produire des chansons. J’ai fait un sondage sur la plupart des publications majeures en rapport avec la synthèse de discours depuis 1975 jusqu’à 2015, et en août 2015, une maquette de Sinsy a été créée. Maintenant, je l’appelle « Synth IV » pour rigoler.
Dorelly : Donc Sinsy était ta première source d’inspiration ?
Kanru : Pas vraiment. C’était juste pour avoir une excellente compréhension de ce qui existait déjà. Pour faire n’importe quelle recherche sérieuse, il faut s’appuyer sur les épaules d’un géant.
Dorally : Qu’est-ce qui t’a donné l’idée de faire ton propre synthétiseur, alors ?
Kanru : Oh, ce n’est pas intéressant si tu ne fais pas ton propre logiciel, donc je suis parti dans cette direction sans vraiment réfléchir. A ce moment-là, je me suis dit que ce serait sympa de faire quelque chose avec une approche hybride entre Vocaloid/UTAU et Sinsy/CEVIO. Et c’est comme ça qu’est arrivé Moresampler, qui était plus ou moins un effort pour améliorer la technologie du côté Vocaloid/UTAU, alors que du côté de l’apprentissage automatique, il y a différentes sous-catégories comme le TLN (Traitement du Langage Naturel) et la modélisation acoustique.
Dorelly : Je vois. Je suppose qu’à un moment, je vais avoir peur d’à quel point Eleanor Forte aura l’air réelle ! Elle est déjà tellement bien développée ; je n’arrive pas à imaginer comment elle sera plus tard ! En parlant d’Eleanor Forte, quelle a été ta réaction quand tu as vu son design pour la première fois ? Je dois être honnête, je l’ai adorée, et je ne pouvais pas m’empêcher de la regarder quand elle a été révélée !
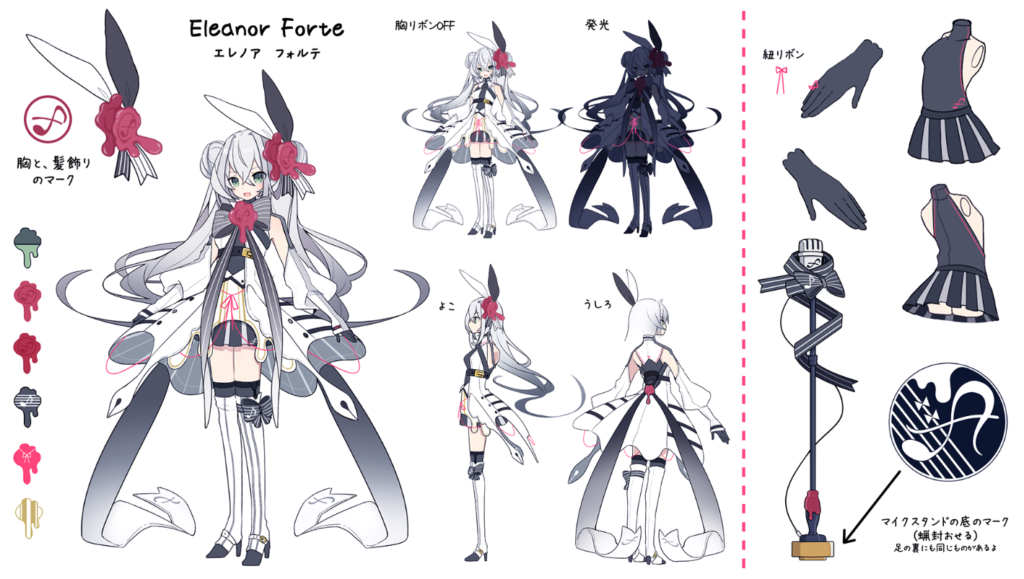
Kanru : Je suis soulagé. J’avais un peu peur que sa voix et son design ne correspondent pas. Elle avait un ratio tête-corps plus grand et une voix plus mature jusqu’à ce qu’on les coordonne début août.
Dorelly : J’adore son design autant que sa voix ! Je suppose qu’on ne saura jamais qui lui a donné sa voix ?
Kanru : En fait, nous avons signé un contrat avec la doubleuse qui interdit de dévoiler toute information personnelle. Au moment du développement, elle ne devait servir que pour des tests internes, et nous voulions éliminer tous les facteurs qui pouvaient entraver ou retarder nos progrès. Mais finalement, nous nous sommes rendus compte qu’elle sonnait mieux que prévu.
Dorelly : Je pense qu’elle devait exister, et je suis contente qu’elle aie finalement été retenue ! Est-ce que, dans le futur, tu penses ouvrir les porte de Synth V à d’autres compagnies pour ajouter des nouveaux personnages ou de nouvelles banques vocales ?
Kanru : J’y pense, mais c’est assez difficile de trouver un partenaire commercial solide. Nous essayons aussi de séparer la technologie et le marketing. Dreamtonics s’occupera toujours du côté technique. Nos clients s’occuperont du côté marketing, et lancer un personnage demande plus de ressources que ce que la plupart des gens pourrait penser.
Dorelly : Je comprends totalement. J’espère vraiment que nous ne verrons pas seulement de nouvelles voix pour de nouveaux personnages, mais aussi plus de promotion pour Eleanor Forte, AiKO et Genbu !
Kanru : Tiens juste ma bière !
Dorelly : En parlant de personnages et de voix, je me suis toujours demandé quelle langue avait été la plus compliquée à implémenter.
Kanru : Je suppose que l’Anglais et le Mandarin étaient à peu près aussi compliqués l’un que l’autre, alors que le Japonais était le plus facile. L’Anglais était compliqué à cause des problèmes de combinaisons (le grand nombre de diphtongues), et la difficulté du Mandarin résidait plus dans les nuances (pas autant de diphtongues, mais il y avait de vilaines triphtongues avec lesquelles il fallait travailler).
Dorelly : Ca a dû très certainement être très intéressant de travailler avec ces langues, tout comme toutes les fonctionnalités que tu as ajoutées à Synth V ! J’en suis arrivée à un point où tout ce que je peux penser, c’est « De quoi avons-nous besoin de plus ! » Ce qui me fait me demander, parmi toutes les fonctionnalités de Synth V, est-ce qu’il y en a une que tu préfère ?
Kanru : Peut-être les Effets Glottiques. Je sais que c’est probablement la fonctionnalité la plus compliquée à maîtriser parmi toutes, mais je peux enfin trouver une place dans le logiciel où glisser le modèle de Liljencrants-Fant. Donc si des collègues chercheurs voient ça, ils sauront « Hey, ce gars qui a fait ça est l’un des notres ».
Dorelly : J’avoue que je dois encore comprendre comment bien les utiliser, mais j’ai prévu de m’y intéresser de plus près, ainsi qu’aux ajouts des futures mises à jour ! J’espère que Synth V va beaucoup s’améliorer avec les temps !
Kanru : La qualité sonore n’a pas encore atteint son paroxysme, et l’amélioration est un processus continu et en cours. Nous avons beaucoup de projets pour ça dans le futur, mais pour l’instant, nous les gardons secrets.
Dorelly : J’ai hâte d’en entendre et d’en voir plus à propos de toi à l’avenir ! Merci beaucoup pour le temps que tu as passé avec nous et d’avoir répondu à nos questions ! C’était très inspirant !
Kanru : Mais de rien ! N’oublie pas de jeter un oeil et de rejoindre notre communauté ! Nous fournirons des petites mises à jour fréquentes basées sur les retours sur notre forum.
Conclusion
Interviewer Kanru Hua était vraiment inspirant, non seulement en tant qu’étudiante de la même filière, mais aussi en tant que fan de Synthétiseurs vocaux ! Le futur de Synthesizer V a l’air brillant, et j’ai hâte d’en apprendre plus, donc je voudrait vous inviter à rejoindre sa communauté via le forum officiel de Synthesizer V ! De plus, le site web d’AniCute a aussi été traduit en Anglais, donc n’hésitez pas à y jeter un oeil et à soutenir Synthesizer V !
N’oubliez pas de jeter un oeil à nos précédents articles sur Synthesizer V, et restez connectés sur VNN avec nous pour toutes les actualités à propos de vos chanteurs virtuels favoris !
Aperçu Technique de Synthesizer V Maintenant Disponible !
La Version Complète de Synthesizer V est Désormais Disponible !
Liens officiels
Site Web Officiel de Synthesizer V
Twitter de Kanru Hua
Site Web d’AniCute


