 VNN Everything about virtual voices, just one click away!
VNN Everything about virtual voices, just one click away!

We talked a lot about Synthesizer V lately, one of the most recent and awaited new synthesizer software, developed by Dreamtonics. We also talked a lot about the newest additions to Synth V’s voice libraries: GENBU, Yamine Renri and, of course, AiKO, its first commercial Chinese voicebank.
Now, I got the chance to interview Kanru Hua and talk with him about their software for VNN! It was really an honor for us and we’re very glad we could interview him. You can read the interview below, hope you enjoy!
Dorelly: Hello and nice to meet you! Thank you so much for letting me interview you! I’m kinda honored actually!
Kanru: No need to be formal lol You’re also a student in Computer Science, right?
Dorelly: Correct, and I’ve always been interested in Synthesizers myself, in fact I was very excited when I first saw your Moresampler for UTAU and my first thought was “Oh my god I’m not alone!”
Kanru: Curiosity is a nice thing to have. I’ve been wanting to create something that’s “sheer overpowered” unlike anything you’ve seen before, haha.
Dorelly: Oh I could feel this aura through Synth V! When did you start working on it?
Kanru: The idea (technology-wise) was around early 2015. But back then the techs were not mature enough for production use. I did a survey on most major publications in speech synthesis from 1975 to 2015 and in August 2015 a mock-up Sinsy was created. I now semi-jokingly refer to it as Synth IV.
Dorelly: So Sinsy was your first inspiration?
Kanru: Not actually. That was just for gaining a solid understanding of existing arts. For any serious research you need to stand on the shoulder of a giant.
Dorelly: So what did give you the idea of making your own synthesizer, then?
Kanru: Oh, if you don’t make one of your own it’s not interesting so it went this way without much thinking. By that point I thought it would be nice to do a hybrid approach of something between Vocaloid/UTAU and Sinsy/CEVIO. So there was Moresampler, more or less as an effort to mature the tech on the Vocaloid/UTAU side, while for the machine learning side of the art, there were different sub areas like NLP (Natural Language Processing) and acoustic modeling.
Dorelly: I see. I guess there will be a point in time where I’ll get scared at how realistic Eleanor Forte is! She’s already so clear now; I can’t imagine how she’ll be in the future! Speaking of Eleanor Forte, what was your reaction when you saw her design for the first time? I need to be honest, I loved it and couldn’t stop staring at it when she got revealed!
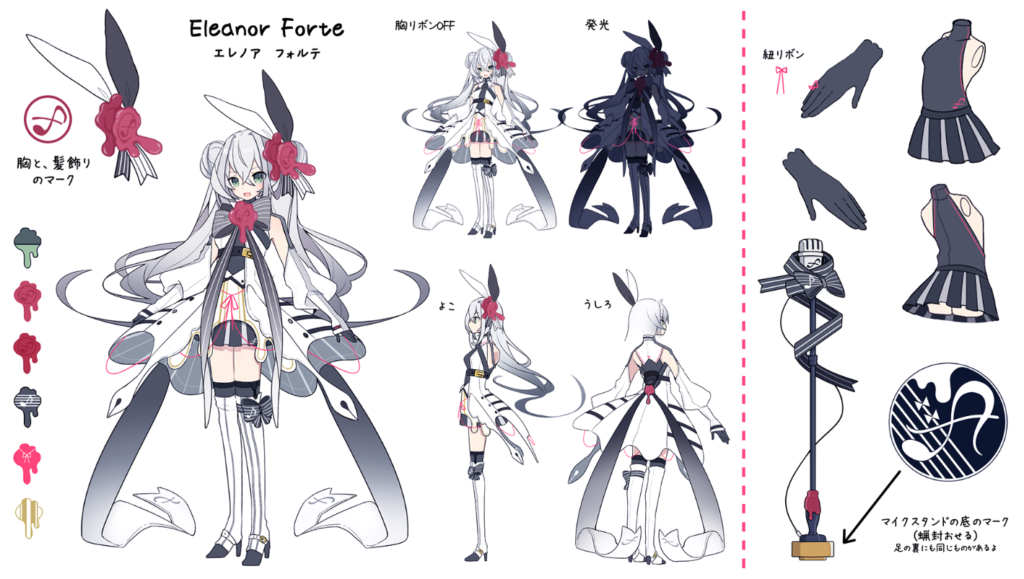
Kanru: I’m relieved. I was kind of afraid that her voice and design wouldn’t match. She had a larger head-to-body ratio and a more mature voice until we pulled them closer on each end in early August.
Dorelly: I really love her design as much as her voice! I guess we will never know who her voice provider is.
Kanru: We actually signed contract with the VP to prevent disclosure of any personal information. At the time of development she was only meant for internal tests, and we wanted to eliminate all factors that could impede or delay the progress. It turned out that she sounds better than expected though.
Dorelly: I think she was meant to be, and I am glad she made it at the end! Do you plan to open Synth V’s doors to other companies for new characters/voicebanks, in the future?
Kanru: I am but it’s kinda hard to find a solid business partner. Also, we’re trying to separate tech and marketing. Dreamtonics will always be on the tech part. Our clients handle the marketing side and launching a character takes more resource than most people would expect.
Dorelly: I can totally understand. I truly hope we will see not only more new character voices, but also more promotion for Eleanor Forte, AiKO and Genbu in the future!
Kanru: Just hold my beer!
Dorelly: Speaking of character and voices, I always wondered which language was the hardest to implement, actually.
Kanru: I guess English and Mandarin Chinese were about equally hard, while Japanese was the easiest. English mostly because of a combinatorial problem (the sheer number of diphones), while Mandarin’s difficulty was more on the nuances (not as many diphones but there were nasty triphones to work with).
Dorelly: Those languages surely must’ve been interesting to work with, just like all the features that you added to Synth V! I’ve come to a point where all I can think is “What could we need more!” Which makes me wonder, among all the featured in Synth V do you have a favorite one?
Kanru: Probably Glottal Effects. I know it’s probably the hardest-to-master feature among all but finally I can find a place in the software to squeeze Liljencrants-Fant model in. So if fellow researcher see this they will know “hey this dude who made this is one of us”.
Dorelly: I admit I’ve yet to still fully understand how to properly use them, but I plan to have a deeper try on them and all the future updates’ additions! I expect Synth V to improve a lot with time!
Kanru: Sound quality hasn’t reached its bottleneck yet and improvement Is a continuous and on-going process. There are lots of plans on that in the future, but for now I will keep them secret.
Dorelly: Can’t wait to hear and see more of you in the future! Thank you so much for your time with us and for answering our questions! It was very inspiring!
Kanru: You’re very welcome! Don’t forget to check and join our community! We will provide small and frequent updates based off of feedbacks in our forum.
Conclusions
Interviewing Kanru Hua was really inspiring both as a student of the same area and, of course, as a fan of vocal Synthesizers! Synthesizer V’s future looks brilliant and I can’t wait to hear more of it, so I would like to invite you on joining its community through Synthesizer V’s official forum! Also, AniCute‘s website has been translated in English as well, so feel free to check it out and support Synthesizer V!
Don’t forget to check out our previous articles about Synthesizer V, and stay tuned on VNN with us for all the news about your favorite virtual singers!
Synthesizer V Technical Preview available now!
Synthesizer V Production Release Available Now!
Official links
Synthesizer V Official Website
Kanru Hua Twitter
AniCute Website


